
[원본]






[번역]
- 초록
- 딥 뉴럴넷은 효율적인 학습을 하기 위해 큰 용량의 데이터를 필요로 하는데, 학습 데이터를 모으는 것은 많은 비용과 노동이 필요하다. 데이터 증강은 이 이슈를 데이터의 레이블을 보존하면서 변환시켜 증강시킴으로서 해결한다. 최근 CNN task 성능을 개선하기 위해 데이터 증강을 폭넓게 사용하고 있다.
- 본 연구는 널리 알려진 다양한 데이터 증강법을 연구자들이 그들의 학습 방법에 적용함에 있어 과학적 이론에 입각한 결정을 내릴 수 있도록 기준을 제공할 것이다. 다양한 기하학적, 광학적 데이터 증강 방법론들의 성능을 비교적 간단한 CNN을 통해 측정했다. 실험 결과는, 4-fold cross-validation과 TOP 1, TOP 5 Accuracy를 활용했을 때, 기하학적 방법인 Cropping이 CNN task 성능을 의미있게 개선했다.
- 소개
- CNN은 딥러닝과 아주 밀접하다. CNN은 계층적인 모델이고 보다 추상적인 고차원의 특징을 포착하는 다층 구조로 표현할 수 있다. CNN의 연결 패턴은 이미지, 음성, 텍스트와 같은 공간적 데이터의 학습과 인지를 가능하게 하는 동물의 시각 대뇌 피질에 영감을 받았다. 최근의 대용량 데이터셋과 컴퓨팅 파워의 발전과 함께 CNN은 다양한 고화질 이미지나 영상 분류를 포함하는 컴퓨터 비전 task에서 최신 기술로 다뤄져 왔다. 하지만 큰 데이터셋은 대중적이지 않고 작은 데이터셋에서 CNN을 학습시키면 Over-fitting이 일어나기 쉬워 사용자의 눈에는 보이지 않는 불변 데이터를 발생시키는 CNN의 역량이 제한되는 문제가 있다.
- 이 문제에 대한 한가지 해결 가능성이 있는 방법은 정형화된 규칙으로 데이터셋을 인공적으로 팽창시켜서 데이터셋의 레이블을 보존하면서 변형해서 모델의 학습이 이미지의 어떤 특징을 찾으면 해당 학습 내용은 더욱 더 불변하도록 데이터 증강(DA, Data Augmentation)을 적용하는 것이다. 통상적으로 DA는 이전부터 ImageNet Large-Scale Visual Recognition Challenge(ILSVRC)에서 CNN 모델 학습에 있어서 Over-fitting을 줄일 수 있으면서 SOTA(State-of the-art) 결과를 성취할 수 있게 해준 방법이었고 컴퓨터 연산적으로 많은 비용을 치루지 않아도 되는 방법이다

- 기하학적 변환은 CNN의 학습이 이미지의 어떤 기하적 특징을 찾으면 해당 학습내용은 불변하도록 방향이나 위치를 바꿔서 이미지의 모양을 변형시킨다. 예를 들면, 뒤집기(flipping), 자르기(cropping), 크기 조정(scaling) 및 회전(rotating)이 있다. 광학적 변환은 CNN이 빛과 색의 변화에 대해 불변하도록 이미지 데이터의 RGB 채널을 조정한다.
- Complex DA는 더 많은 학습 데이터를 생성하기 위한 분야별 합성을 이용해 데이터셋을 인공적으로 팽창시키는 체계이다. 이 체계는 [Rogez and Schmid, 2015; Peng et al., 2015]의 학습 데이터를 통상적인 DA 방법론들과 비교하는 능력을 가진 richer를 생성한 것으로 더욱 유명해졌다. 예를 들면, [Masi et al., 2016]은 더 적은 데이터로도 SOTA 얼굴 인식 시스템과 유사한 성능을 내는 얼굴 모습의 다양성을 증가시키는 다양한 얼굴 표정을 합성한 데이터를 이용한 얼굴 인식 시스템을 개발했다. 데이터 합성 분야의 최첨단인 GAN에서는 데이터의 일부를 추출해서 새로운 데이터를 만들어낸다. 예를 들면, [Zhang et al., 2016]에서는 GAN의 구조를 쌓아서 text 서술로부터 진짜 같은 새와 꽃 이미지를 생성했다.(역자 주: Stage-1 에서는 오직 text 서술 만 가지고 이미지를 생성하고 real image를 다시 input 이미지로 넣고 Stage-2 에서 더욱 정교한 이미지를 생성)
- 그러므로, DA는 CNN의 성능은 개선하고 over-fitting은 예방하는 방법론이라고 할 수 있다. DA는 특히 데이터 수집의 노동력이나 학습 데이터의 양이 제한적일 때 적합하다. Complex DA는 강력한 데이터 증강 체계이지만, 막대한 연산 비용과 소요 시간을 필요로 한다.
- 널리 알려진 다양한 DA 방법론을 요약한 결과는 표1에 있다. [Chatfield et al., 2014]는 3가지 방법의 DA 방법론만 측정하고 있지만, 일반적인 데이터로 CNN 구조를 가진 서로 다른 모델들의 성능이 어떻게 다른지 측정했다. 이 연구의 주요 초점은 깊고 얇은 인코딩 방법론 딥러닝 구조에 대해 엄격하게 측정하는데 맞춰져 있다. DA의 3가지 방법은 뒤집기(flipping), 복합 뒤집기(flipping) 및 자르기(cropping)이고 학습 이미지는 coarse grained 데이터인 Caltech 101과 Pascal VOC이다. 그리고 저자의 실험은 낮은 수행성능을 보이긴 했지만, gray-scale 이미지로 CNN을 학습시켰다. 종합적으로 결과는 복합 뒤집기(flipping)와 자르기(cropping)가 2~3% 정도 나은 성능을 나타냈다. 이 연구의 단점은 적은 종류의 DA 방법론만 측정했다는 점이다.
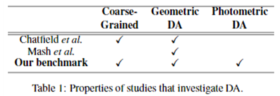
- [Mash et al., 2016]은 항공기 분류 작업에 대한 다양한 기하학적 DA 방법을 10개 Class의 fine-grained 데이터셋을 사용해서 제시했다. 실험한 DA 방법에는 자르기(cropping), 회전(rotating), 크기 조정, polygon occlusion(역자 주. 다각형의 회색 노이즈 추가) 및 이러한 방법들의 조합이 포함되었다. polygon occlusion과 자르기(cropping) 방식의 조합은 기준 성능보다 9% 향상된 가장 좋은 성능을 나타냈다. 이 연구는 다양한 DA 방법론을 평가했지만 광학적 평가는 포함되지 않았고 coarse-grained 데이터셋에 대한 연구가 없었다. 이 연구와 관련된 추가 연구인 [Dilemanet al., 2015]에서는 특정 DA 방법은 fine-grained 데이터셋에 특히 이점이 있다고 언급했다. 예를 들면 fine-grained 데이터셋 중에서 은하(galaxy) 형태 분류에 있어서 회전(rotating) DA 학습 이미지를 쓰면 CNN의 task 성능을 증가시킬 수 있다고 적었다.
- 하지만, 현재까지, 각각의 큰 coarse-grained 데이터셋에 대해 어떤 DA가 가장 적절한 방법인지 평가한 포괄적인 연구가 없었다. 이런 이유로 본 연구의 목적은 coarse-grained 데이터셋인 Calthec101 데이터셋에 대해 다양한 기하학적, 광학적 DA 체계를 적용해보고 평가하기로 했다. 사용한 간단한 CNN모델은 [Zeiler and Fergus, 2014]의 모델이고, 연구의 목표는 학계에서 경험적으로 적용하고 있는 각 연구자들의 데이터셋에 대한 DA 방법에서 더 적절한 DA 방법을 선택할 수 있게 기여하는 것이다.
- DA 방법론
- DA란 어떤 방법으로든 원본 학습 데이터셋을 레이블은 보존하면서 변형하여 데이터셋을 인공적으로 팽창시키는 것을 말하며 이는 다음과 같은 매핑(mapping)으로 표현할 수 있다.
Φ = S → T
- 여기서 S는 원본 학습 데이터를, T는 S로부터 증강한 데이터셋을 말한다. 인공적으로 팽창한 학습 데이터는 그러므로 다음과 같이 표현할 수 있다.
S’ = S ∪ T
- 여기서 S’은 원본 학습 데이터셋과 Φ로 정의된 각각의 변형된 데이터셋을 포함하고 있다. 레이블을 보존하면서 변형함(label preserving transformations)이라는 말은 만약 이미지 x가 클래스 y의 요소인 이미지라면 Φ(x)인 이미지도 역시 클래스 y의 요소라는 뜻이다.
- 레이블을 보존한다는 제약을 만족하는 Φ(x)는 그 종류와 방법이 무한하기 때문에, 본 연구에서는 널리 알려진 DA 방법들만 평가하며, 그 대상은 [Chatfield et al., 2014], [Mashet al., 2016]의 연구와 그 외에 또 다른 한 가지 새로운 DA 방법(Section 2.2 참조)으로 한다. 특별히, 이 7가지의 방법론을 평가했고(figure 2), 이 7가지 방법 중 첫 번째는 원본 데이터셋만으로(No-Augmentation)로 해서 벤치마크로 삼았고 3가지 기하학적 DA 방법론과 3가지 광학적 DA의 기준으로 삼아 연구를 수행했다.

- 기하학적 방법론
- 기하학적인 방법론은 이미지 각각의 픽셀 값을 새로운 위치에 매핑하는 방식으로 변환하는 것을 말한다. 이미지의 기본 모양은 유지하지만, 자세나 방향이 고쳐진다. 이와 관련된 성과를 낸 연구로는 [Krizhevskyet al., 2012; Dielemanet al., 2015; Razavianet al., 2014]가 있다. 우리는 뒤집기(flipping)와 회전하기(rotating), 자르기(cropping)를 연구했다.
- 뒤집기(flipping)는 수직의 축으로 이미지를 뒤집는 것으로 거울에 비치는 이미지와 같다. 이 방법은 가장 많이 사용되는 DA 방법 중 하나이며 [Krizhevskyet al., 2012]의 연구가 유명하다. 이 방법은 컴퓨터 연산적으로도 효율적이고 오직 이미지 행렬 값의 행만 반전하면 되기 때문에 수행하기 쉽다.
- 회전하기(rotating)는 이미지의 중심을 두고 각 픽셀(x, y)의 값을 (x’, y’)로 움직이는 방법이고 [Dielemanet al., 2015; Razavianet al., 2014]의 연구에서는 다음과 같이 제시하고 있다.:
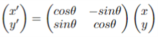
- 해당 연구에서는 θ의 값을 –30° ~ +30°로 설정하면 충분히 모델 성능 개선에 유의미한 증강 이미지 데이터를 생성할 수 있다고 제시했다.
- 자르기(cropping)는 또 다른 유명한 DA 방법으로 [Krizhevskyet al., 2012]의 연구가 널리 알려져 있다. 우리는 앞서 선행연구로 소개했던 [Chatfieldet al., 2014]에서 수행했던 이미지의 중심으로부터 256 × 256으로 한 장, 이미지의 각 모서리에서부터 224 × 224 까지만 포착해서 잘라내는 방법과 동일하게 수행했다.
- 광학적 방법론
- 광학적 변형은 이미지의 RGB 채널 각각의 픽셀 값 (r, g, b)를 사전에 정의된 규칙에 따라 새로운 픽셀 값(r’, g’, b’)으로 치환하는 방법이다. 이런 조정은 이미지의 명도와 색조는 조정하면서 기하학적 데이터는 변동되지 않습니다. 우리 연구진은 Colour Jittering, Edge Enhancement, Fancy PCA를 연구했다.
- Colour Jittering의 종류에는 [Wuet al., 2015]의 Random Colour Jittering, [Razavianet al., 2014]의 Set Colour Jittering이 있는데 우리는 HSB 필터를 쓰면 이해와 접근이 용이한 후자의 방법을 선택했다.
- Edge Enhancement는 새로운 DA 방법으로 이미지 내에 표현된 클래스의 윤곽선을 강조하는 방법이다. CNN의 학습된 커널이 모양을 식별하기 때문에, 강조된 윤곽선을 가진 학습 데이터셋을 모델에 넣으면 모델의 성능이 향상될 것이라는 가설이 세워졌다. 이 DA 방법은 아래 제시된 Algorithm 1에 따라 수행한다. 윤곽선을 필터링하는 방법은 [Gonzalez and Woods, 1992]의 Sobel 이라는 윤곽선 검출기에 의해 검출 가능하고, 이때, 윤곽선은 이미지 S에 대한 각각의 픽셀에 대해 local gradient ▽S(i, j)를 계산하면 알 수 있다.

- Fancy PCA는 학습 이미지에 주성분(principles components) 값을 스케일링해서 더해서 증강 이미지를 만드는 방법이다. 관련 연구 [Krizhevskyet al., 2012]에서 PCA를 개별 이미지 또는 전체 데이터셋으로 수행했는지는 불분명하다. 본 연구에서는 본 연구진의 컴퓨팅 파워와 메모리 문제로 전자의 방법을 채택했다.
- CNN 아키텍쳐
- CNN 아키텍쳐는 tradeoff를 가지는 task의 성능과 학습 속도 간에서 더 유리한 절충안을 얻기 위해 개발되었다. 본 연구진의 모델은 4-fold cross validation를 적용한 8,500 ~ 42,500개의 이미지 데이터셋에 대해 7번 학습을 실시했기 때문에 학습 속도가 매우 중요했다. 또한 네트워크가 학습 데이터에 맞게 충분히 깊어야(충분한 parameters 포함) 했다.
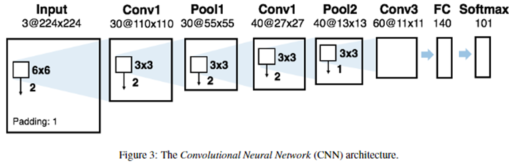
- 본 연구진은 [Zeiler and Fergus, 2014]에서 설명한 것과 유사한 아키텍쳐(그림 3)을 사용했다. 이 연구에서는 모델의 네트워크 계층의 깊이와 학습 속도 간의 tradeoff 관계에서 합리적인 절충안을 제시했다. 이 아키텍쳐는 5개의 학습 가능한 레이어로 구성되어 있다. 3개는 convolutional layer이고, 1개는 fully connected layer, 1개는 softmax layer이다. 이 CNN 모델은 255*255 사이즈를 가지는 이미지의 3개의 채널(이미지의 RGB 채널)을 입력받아 30개의 필터를 가지는 커널사이즈 6*6, stride 2, padding 1로 합성곱을 수행하고 30*110*100 사이즈의 feature map을 생성한다. 이 레이어는 커널사이즈 3*3, stride 2로 이루어진 max-pooling 필터로 압축되어 30*55*55 형태의 feature map을 산출한다. 이전과 동일한 커널사이즈와 stride로 구성된 40개의 필터를 거치며 40*27*27 형태의 새로운 feature map을 생성한다. 이어서, 다시 커널사이즈 3*3, stride 1을 가지는 max-pooling 필터로 압축해서 40*13*13의 feature map을 생성한다. 이어서 3*3 사이즈, stride 1인 60개의 필터를 거쳐 60*11*11개의 parameter를 레이어를 생성해서 CNN 마지막 레이어에 넘긴다. 마지막으로 140개 레이어의 fully connected layer를 거쳐 101개의 softmax 레이어를 거쳐 결과물이 생성된다.
- pooling을 중첩함으로서 CNN의 성능을 높이고 over-fitting을 경감시킬 수 있었다[Krizhevskyet al., 2012]. 이것은 동일한 feature map에서 이웃한 뉴런 그룹의 중첩된 부분을 더해서 산출했다. 크기가 증가해도 성능이 크게 향상되지 않았기 때문에 140개의 뉴런으로 구성된 fully connected 레이어가 선택되었다[Chatfieldet al., 2014]. 이 연구에서는 더 작은 레이어를 가지는 게 더 나은 분류 클래스의 구축에 있어 더 유리한 인코딩이 된다는 것을 보여주었다. 개별 convolution 레이어의 깊이 수준은 여러번의 실험을 통해 결정했다. 더 많은 합성곱 레이어는 성능을 크게 증가시키지 않아 연산 시간을 줄이기 위해 생략했다. 또한, 추가적인 fully connected layer가 모델의 성능을 더 향상시키지 않는 것을 알아냈다.
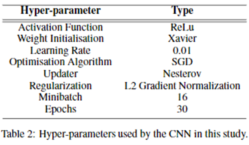
- 모든 뉴런은 평균 0, 표준편차 0.01인 가우스 분포에서 초기화된 가중치를 사용하여 보정된 Linear Unit[Hahnloset al., 2000]을 사용했다. Xavier로 알려진 Initialization scheme[Glorot and Bengio, 2010]을 사용해 local minima로 천천히 수렴하는 현상을 완화했다. Adam[Kingma and Ba, 2014]과 Adagard[Duchiet al., 2011]를 포함한 다양한 업데이트 기능을 테스트했지만, 우리는 비교적 빠르게 수렴하고 수치 불안정성과 정체에 시달리지 않는 0.90의 momentum을 가진 Nesterov[Nesterov, 1983]를 선택했다. 추가적으로 정규화는 overfitting을 줄이기 위해 5*10-4의 L2로 gradient normalization을 사용했다. activation function, 학습 속도, 최적화 알고리즘 및 업데이터에 대한 하이퍼파라미터는 관련 작업에 사용된 파라미터를 기반으로 했으며[Krizhevskyet al., 2012] 다른 모든 파라미터 값은 탐색 실험에 의해 결정되었다. 이 연구에 사용된 모든 CNN 하이퍼파라미터는 표 2에 제시되어 있다.
- 실험
- 본 연구는 총 91,44개의 이미지가 포함된 102개의 클래스로 구성된 coarsed-grained 데이터셋인 Calthech 101 데이터셋에서 다양한 DA 방법을 평가했다. Caltech101 데이터 세트는 많은 양의 다양한 클래스를 포함하는 CNN 모델 학습을 위한 잘 정리된 데이터 세트[Chatfieldet al., 2014; Zeiler and Fergus, 2014]이기 때문에 선택되었다. 모델 학습에는 Caltech101 데이터셋의 대부분의 이미지가 사용되었다. 즉, 칼텍101 데이터 세트의 배경 Class를 포함한 상관없는 이미지 725개 이미지가 생략됐다. 또한, cross-validation을 위해 모든 Class의 cardinality를 4로 나누는 추가 작업을 진행했고, 이는 이미지를 몇 장 더 제외했고 총 8,421개의 이미지를 평가했음을 의미한다.
- 우리는 선택된 이미지의 사용을 극대화하고 CNN의 성능이 다른 모르는 데이터셋으로 어떻게 확장될지 더 잘 파악할 수 있기 위해서 cross-validation을 사용하기로 결정했다. 특히 데이터셋을 4개의 동일한 크기의 하위 집합으로 분할하는 4-fold 4 cross-validation이 사용되었으며 여기서 3개의 하위 집합은 학습에 사용되고 나머지 하나는 validation 데이터셋으로 사용되었다. 데이터셋 내의 모든 이미지들은 256×256 크기로 변환되었으며, 여기서 모든 이미지들은 256×256의 크기로 축소되었다.
- 이 축소된 이미지는 256×256 검정색 배경 위에 중앙에 그려졌다. 이를 통해 모든 DA scheme이 고정된 해상도 256×256으로 전체 이미지에 액세스할 수 있게 되었다. 마지막으로 변환된 이미지의 모든 픽셀 값은 [0,255] → [0,1]의 스케일링하여 정규화를 거쳤습니다. 모든 CNN 모델은 30 Epoch의 학습을 거쳤다.
- 이 값은 매 epoch마다 validation, test 데이터셋에 대한 스코어에 의해 결정되었습니다. 모든 구현은 DL4j를 사용하여 Java 8에서 완료되었으며, 실험은 NVIDIA Tesla K80GPU에서 CUDA를 사용하여 수행되었다. 모든 소스 코드와 실험 세부 사항은 온라인에서 확인할 수 있다.
- 결과 및 토의
- 표 3은 실험 결과를 제시하며, 여기서 Top-1 및 Top-5 점수는 오류율이 아닌 정확성을 보고하지만 ImageNet 경쟁에서와 같이 백분율로 평가되었다[Russakovsky al., 2016]. CNN의 출력은 모든 class에 대한 다항 분포(∑Pclass = 1)이다.

- Top-1 점수는 모든 테스트 이미지에서 가장 높은 확률이 올바른 타겟에 매칭된 경우의 점수이다. Top-5 점수는 상위 5개 확률 내에 올바른 레이블이 포함된 횟수이다. cross-validation을 사용하여 CNN의 정확도를 평가함에 따라 표준편차가 모든 결과와 연관되었고, 따라서 결과가 서로 다른 testing fold에 걸쳐 얼마나 편차가 날 수 있는지 알 수 있다. 표 3에서, 기하학 및 광학적 DA 방법 각각의 최고 TOP 1과 TOP 5점 점수를 굵게 표시했다. 결과는 DA를 적용하는 모든 경우에 CNN 분류 작업 성능이 향상되었음을 나타낸다. 특히, 기하학적 DA 테크닉은 Top 1점 및 Top 5점 측면에서 광학적 DA 방법을 능가했다. 예외는 뒤집기(flipping) 방식인 Top-5 점수가 Fancy PCA Top-5 점수보다 낮은 것이었다. 모든 DA 방법에 대해 0.5% ~ 1%의 표준편차는 cross validation을 통해 모든 fold에서 유사한 결과를 나타낸 것을 알 수 있다.
- 자르기(cropping) 방식은 분류 정확도가 13.82% 향상되어 CNN 모델의 Top-1 점수가 가장 크게 향상되었다. 또한 Top-5 분류는 DA가 task를 개선한다는 관련 연구[Chatfield al., 2014; Mash al., 2016]를 입증했다. 우리는 자르기(cropping) 방식이 다른 DA 방식보다 샘플 이미지를 더 많이 생성하기 때문에 다른 방법보다 성능이 우수하다고 판단했다. 이러한 학습 데이터의 증가는 overfitting 가능성을 줄이고 이미지 generalization을 개선하여 전체 분류 작업 성능을 향상시킨다. 또한, 자르기(cropping)는 CNN이 다른 DA 테크닉에서 얻을 수 없는 이점인 [Chatfield et al., 2014]의 연구 결과를 학습 이미지에 더 수용적인 관점을 가져갈 수 있는 변형을 보여준다.
- 하지만 광학적 DA 테크닉은 기하학적 DA 테크닉에 비해 성능이 크게 개선되지 않았다. 가장 우수한 성능을 보여준 광학적 DA 테크닉은 Top-1 스코어로는 baseline 대비 1.44% 향상된 colour jittering이었고 Top-5 스코어로는 3.04% 향상된 Fancy PCA였다. 그리고 Fancy PCA의 Top-1 스코어는 baseline 대비 1.28% 향상되어 [Krizhevsky et al., 2012]의 연구 결과를 뒷받침했다.
- 우리는 또한 colour jittering 방식이 다른 광학적 DA 테크닉에 비해 원본 이미지를 더 많이 변화시키는 증강 이미지를 생성했기 때문에 가장 우수한 Top-1 스코어가 나왔다고 판단했다. 또한 edge enhancement는 제일 성능을 내지 못했는데 이는 섹션 2.2에서 언급했던 것처럼 변환된 이미지가 원본 이미지에 overlay 했기 때문에 윤곽선이 충분히 강조되지 않고 오히려 이미지가 밝아지기만 했기 때문일 수 있다. 하지만, coarse-grained 데이터셋에 대한 CNN Classify task 성능 개선에 있어서 기하학적 테크닉과 광학적 테크닉 중에 어느게 더 우수한지에 대한 정확한 매커니즘은 추가적인 연구가 필요하다.
- 결론
- 본 연구는 DA가 CNN Classify task 성능을 높이는 효과적인 방법이라는 것을 보여준다.
- 특히, 비교적 간단한 CNN 아키텍쳐를 사용하여 다양한 DA 테크닉을 평가한 결과, coarse-grained 데이터셋(Calteck 101)에 대해서는 기하학적 DA 테크닉이 광학적 DA 테크닉보다 우수하다는 결론을 얻을 수 있었다.
- 가장 우수하게 Top-1 스코어를 상승시킨 DA 테크닉은 13.82% 개선한 자르기(cropping)였다. 이러한 결과는 단순하게 광학적인 이미지 변경보다는 형상 자체를 변경하는 테크닉을 써서 coarse-grained 학습 데이터를 증강하는 것이 중요하다는 것을 나타낸다.
- 향후 연구는 Caltech 101 데이터셋을 사용해서 얻은 결과가 다른 데이터셋에도 적용 가능한지 여부를 확인하기 위해 다양한 coarse-grained 데이터셋으로 실험하는 방향으로 진행할 것이다. 또한 다른 CNN 아키텍쳐와 다른 DA 방법들에 대한 연구도 수행할 것이다.
'Data Analysis' 카테고리의 다른 글
| 다크모드 쓰는 사람들을 위한 폰트 컬러 (2) | 2022.08.20 |
|---|---|
| 쉽게 쓰는 Torch FID Score 모듈 (0) | 2022.08.20 |
| Crawling in NAVER Financial Summary, Make PEG/EPS Growth Rate/OPM Growth Rate etc: 네이버 파이낸셜서머리 크롤링해서 PEG, EPS성장율, 영업이익증가율 등 만들고 차트 그리기 (0) | 2022.04.22 |
| sklearn Scaler (0) | 2022.02.19 |
| 타이타닉 결측치도 예측해서 풀어보기(Ridge, RandomForest, Linear Regressor, XGBoost) (0) | 2022.02.12 |




댓글